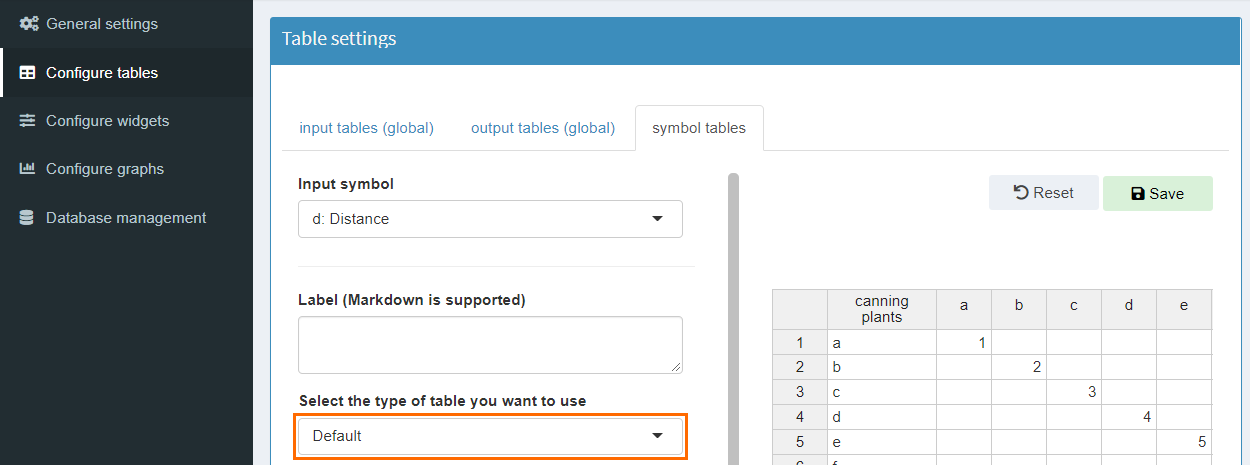
MIRO has an API that allows you to use custom input
widgets such as charts to produce input data. This means
that input data to your GAMS model can be generated by
interactively modifying a chart, a table or any other
type of renderer.
Before reading this section, you should first study the
chapter about
custom renderers. Custom widgets are an extension of custom renderers
that allow you to return data back to MIRO.
Note:
The API of the custom input widgets has been changed
with MIRO 2.0. Documentation for API version 1 (MIRO
1.x) can be found in the
MIRO GitHub repository.
To understand how this works, we will look at an example
app that allows you to solve
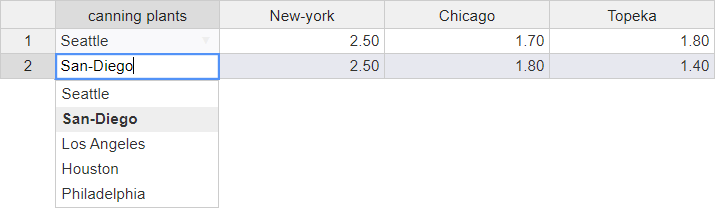
Sudokus. We would like to visualize the Sudoku in a 9x9 grid
that is divided into 9 subgrids - 3x3 cells each. We will
use the same tool that we use to display input tables in
MIRO, but we could have used any other R package or even
a combination of those. Let's first look at the
boilerplate code required for any custom input widget:
mirowidget_<symbolName>Output <- function(id, height = NULL, options = NULL, path = NULL){
ns <- NS(id)
}
renderMirowidget_<symbolName> <- function(input, output, session, data, options = NULL, path = NULL, rendererEnv = NULL, views = NULL, ...){
return(reactive(data()))
}
You will notice that the boilerplate code for custom
widgets is almost identical to that of
custom renderers. The main difference to a custom renderer is that we
now have to return the input data to be passed to GAMS.
Note that we return the data wrapped inside a
reactive expression. This will ensure that you always return the current
state of your data. When the user interacts with your
widget, the data is updated.
The other important difference from custom renderers is
that the data argument here is also a reactive
expression (or a list of reactive expressions in case you
specified additional datasets to be communicated with
your widget), NOT a
tibble.
Let's get back to the Sudoku example we mentioned
earlier. We place a file
mirowidget_initial_state.R
within the custom renderer directory of our app:
<modeldirectory>renderer_sudoku. The output and render functions for custom widgets
should be named
mirorwidget_<symbolName>output
and
renderMirowidget_<symbolName>
respectively, where
symbolName is the lowercase
name of the GAMS symbol for which the widget is defined.
To tell MIRO about which input symbol(s) should use our
new custom widget, we have to edit the
sudoku.json file located in the
<modeldirectory>/conf_<modelname>
directory. To use our custom widget for an input symbol
named
initial_state in our model, the following
needs to be added to the configuration file:
{
"inputWidgets": {
"initial_state": {
"widgetType": "custom",
"rendererName": "mirowidget_initial_state",
"alias": "Initial state",
"apiVersion": 2,
"options": {
"isInput": true
}
}
}
}
We specified that we want an input widget of type
custom for our GAMS symbol
initial_state. Furthermore, we declared an
alias for this symbol which defines the tab title. We
also provided a list of options to our renderer
functions. In our Sudoku example, we want to use the same
renderer for both input data and output data. Thus, when
using our new renderer for the input symbol
initial_state, we pass an option
isInput with the value true to our
renderer function.
Note:
For backward compatibility reasons, you currently
need to explicitly specify that you want to use API
version 2 for custom input widgets. In a future
version of MIRO, this will become the default.
Let's concentrate again on the renderer functions and
extend the boilerplate code from before:
mirowidget_initial_stateOutput <- function(id, height = NULL, options = NULL, path = NULL){
ns <- NS(id)
rHandsontableOutput(ns('sudoku'))
}
renderMirowidget_initial_state <- function(input, output, session, data, options = NULL, path = NULL, rendererEnv = NULL, views = NULL, ...){
output$sudoku <- renderRHandsontable(
rhandsontable(if(isTRUE(options$isInput)) data() else data,
readOnly = !isTRUE(options$isInput),
rowHeaders = FALSE))
if(isTRUE(options$isInput)){
return(reactive(hot_to_r(input$sudoku)))
}
}
Let's disect what we just did: First, we defined our two
renderer functions
mirowidget_initial_stateOutput
and
renderMirowidget_initial_state.
Since we want to use the R package
rhandsontable
to display our Sudoku grid, we have to use the
placeholder function
rHandsontableOutput as well as the
corresponding renderer function
renderRHandsontable. If you are wondering what
the hell placeholder and renderer functions are, read the
section on
custom renderers.
Note that we use the option isInput we
specified previously to determine whether our table
should be read-only or not. Furthermore, we only return a
reactive expression when we use the renderer function to
return data - in the case of a custom input widget. Note
that for input widgets, we need to run the reactive
expression (data()) to get the tibble with our
input data. Whenever the data changes (for example,
because the user uploaded a new CSV file), the reactive
expression is updated, which in turn causes our table to
be re-rendered with the new data (due to the reactive
nature of the renderRHandsontable function).
The concept of reactive programming is a bit difficult to
understand at first, but once you do, you'll appreciate
how handy it is.
A detail you might stumble upon is the expression
hot_to_r(input$sudoku). This is simply a way
to
deserialize
the data coming from the UI that the
rhandsontable
tool provides. What's important is that we return an R
data frame that has exactly the number of columns MIRO
expects our input symbol to have (in this example
initial_state).
That's all there is to it! We configured our first custom
widget. To use the same renderer for the results that are
stored in a GAMS symbol called result, simply add
the following lines to the
sudoku.json file. Note that we
do not set the option isInput here.
"dataRendering": {
"results": {
"outType": "mirowidget_initial_state"
}
}
The full version of the custom widget described here as
well as the corresponding GAMS model
Sudoku can be found in the MIRO model library.
There you will also find an example of how to create a
widget that defines multiple symbols. In this case, the
data argument is a named list of reactive
expressions, where the names are the lowercase names of
the GAMS symbols. Similarly, you must also return a named
list of reactive expressions. Defining a custom input
widget for multiple GAMS symbols is as simple as listing
all the additional symbols you want your widget to define
in the
"widgetSymbols" array
of your widget configuration. Below you find the
configuration for the initial_state widget as
used in the Sudoku example.
"initial_state": {
"widgetType": "custom",
"rendererName": "mirowidget_initial_state",
"alias": "Initial state",
"apiVersion": 2,
"widgetSymbols": ["force_unique_sol"],
"options": {
"isInput": true
}
}
In addition to defining a widget for multiple symbols,
MIRO also allows you to access values from (other) input
widgets from your code. To do this, you must list the
symbols you want to access in the
"additionalData"
array of your configuration.
Note that custom widgets cannot be automatically expanded
to use them for
Hypercube jobs. Therefore,
if you include scalar symbols in custom widgets (either
as the symbol for which the widget is defined or via
"widgetSymbols") and
still want to include these symbols in the Hypercube job
configuration, you must also define a scalar widget
configuration for Hypercube jobs. You can do this with
the
"hcubeWidgets"
configuration option. Below you will find an example of
the scalar
force_unique_sol, which is to
be used both as a custom widget and as a slider in the
Hypercube module:
{
"activateModules": {
"hcubeModule": true
},
"hcubeWidgets": {
"force_unique_sol": {
"widgetType": "checkbox",
"alias": "Force initial solution",
"value": 1,
"class": "checkbox-material"
}
},
"inputWidgets": {
"force_unique_sol": {
"widgetType": "custom",
"rendererName": "mirowidget_force_unique_sol",
"alias": "Initial state",
"apiVersion": 2,
"widgetSymbols": ["initial_state"],
"options": {
"isInput": true
}
}
}
}
The checkbox is then expanded to a dropdown menu in the
Hypercube submission dialog (see
this table, which widgets are supported and how they are expanded
in the Hypercube submission dialog).